
- @salesient
We have been wrangling biodiversity data since 2009, to prepare these for publication on the Global Biodiversity Information Facility (GBIF), a data aggregator for worldwide species occurrence data. We used Excel, small scripts, or complicated SQL statements to standardize our data to the right format, before we could actually publish the data to the GBIF network. And after the actual publication, we would almost always find small or big errors we've missed.
In late 2011 we discovered a new tool, which changed the way we were working completely: Google Refine - now called OpenRefine. Since then we never publish any data before we have processed it with this tool. OpenRefine is a local browser application, used for data cleanup and transformation. It looks a bit like a spreadsheet, but behaves more like a procedural script on tabulated data. Where in a spreadsheet the cells are the essence, in OpenRefine the columns are the core of the tool. For example, by creating a facet of the unique values in a column, you quickly get a sense of the data. And it is not only about showing these different values, you can also cluster these values and correct misspellings in bulk. Another advantage of OpenRefine is that its interface is really intuitive and all actions preformed on a dataset are stored, which allows you to reuse them one another version of the source data or similar datasets. Excellent!
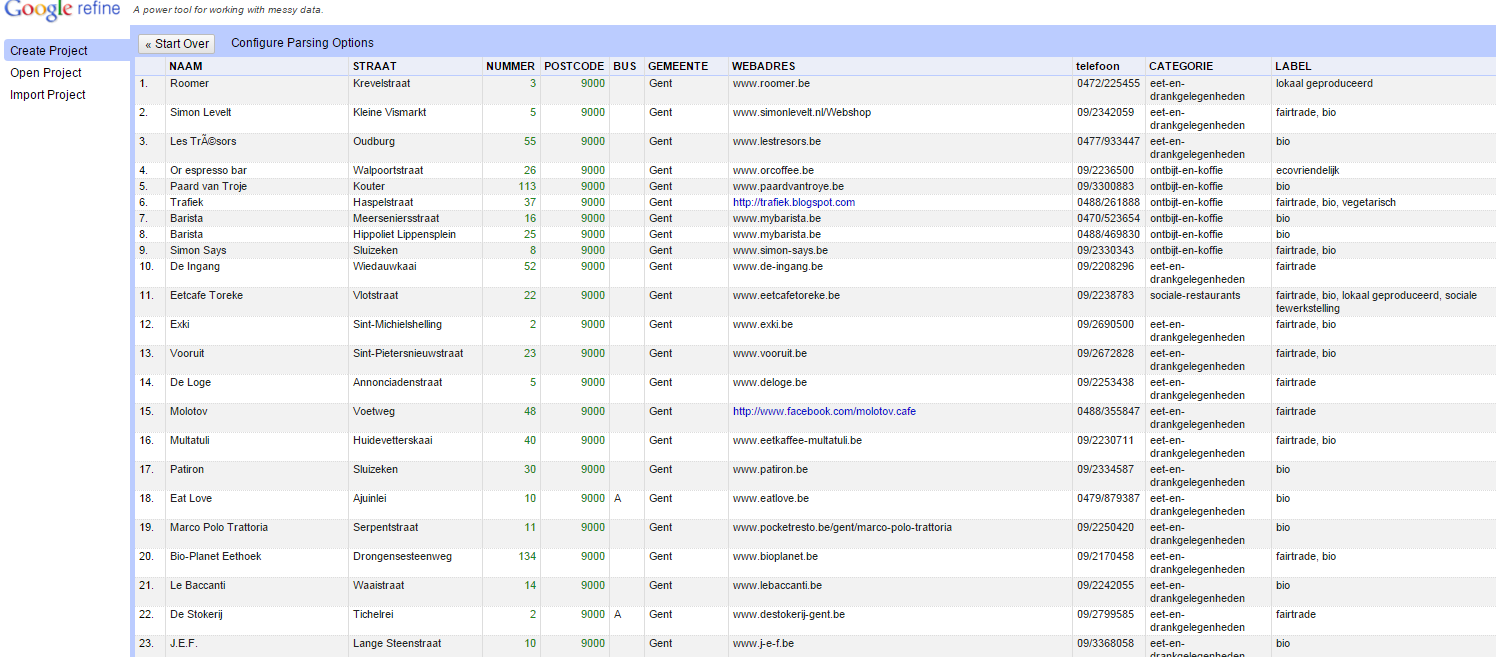
So, whether you are an open data publisher or user, you have probably also encountered loads of messy data: variations of the same value, inconsistent date formats, misspelled text, etc. How do you explore, let alone clean such data, without advanced scripting knowledge? Well, OpenRefine does the job, by cleaning it, transforming it from one format into another, or extending it with web services and external data. OpenRefine works quite well for datasets up to 100.000 rows and is supported by a large open source community.
Interested in an introduction? Join us at our workshop during the Open Belgium 2016 conference! This workshop contains a theoretical and hands-on session, so bring your own computer and data!
Written by


Share